Mídia Faren - Guia Completo (HTML)
Esta página contém as mesmas informações técnicas do README.md, com visual organizado.
Ilustrações do projeto

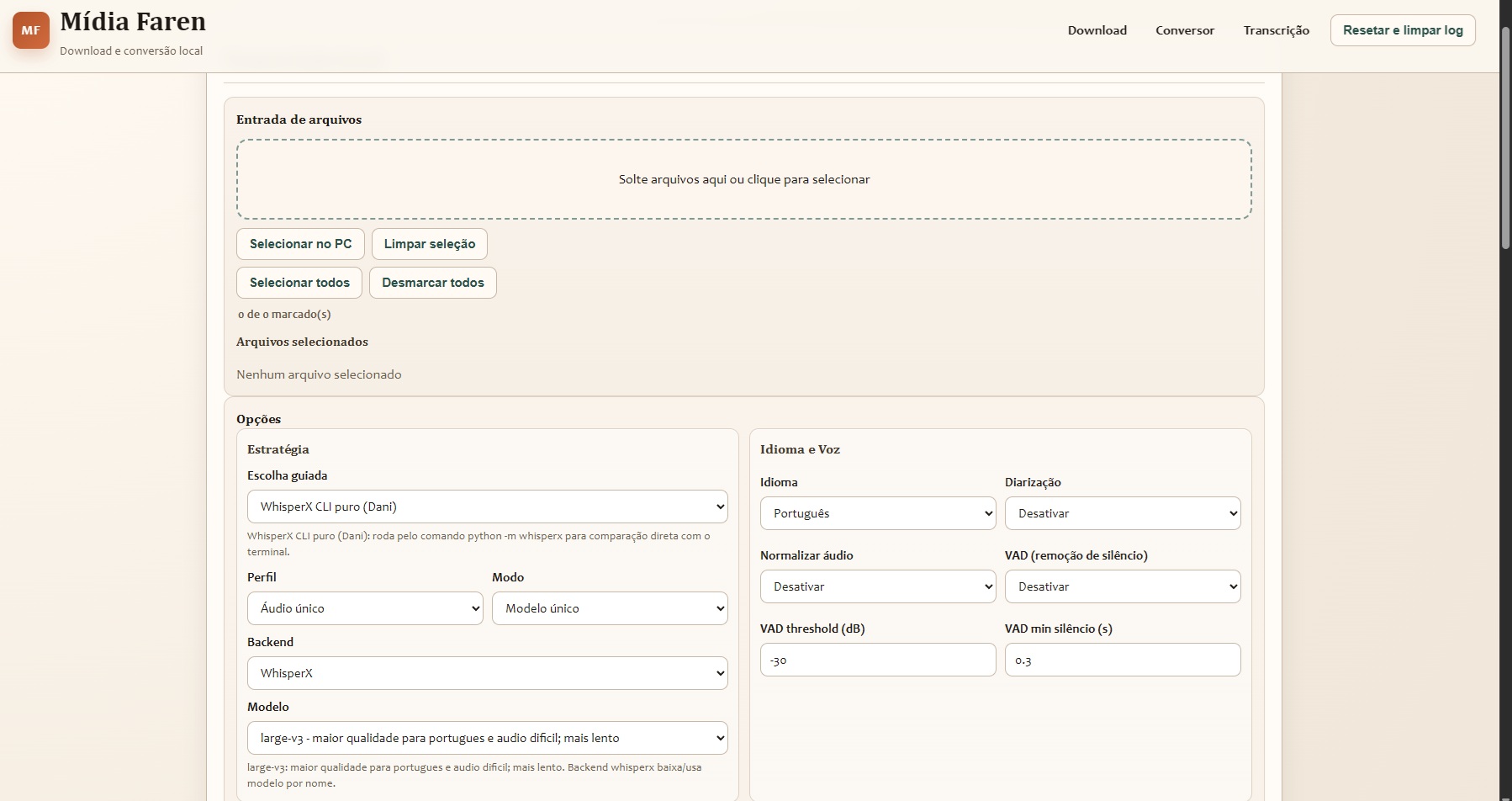
Áudio de exemplo incluído para teste imediato
- Arquivo:
data/Oneshot-ODiaboDoPoco-Terca.ogg - Contexto: one-shot no cenário de The Witcher
- Mesa: 3 jogadores
- Sistema: DND 5e 2024
Player do exemplo
Ouvir exemplo OGG (link direto)
Use este arquivo para validar transcrição, marcação de tempo/falantes, glossário e o fluxo de resumo.
Links rápidos desta documentação:
- MODELOS_DOWNLOAD.txt (download dos modelos + destino)
- SMOKE_TEST_10_MIN.md (checklist rápido de validação)
- README.md (guia completo em Markdown)
1) O que este pacote contém
app.py: servidor Flask da aplicação.executar.bat: instalador/validador automático + inicialização.mfaren/: backend principal (download, conversão, transcrição, filas, jobs).static/etemplates/: frontend.instalacao_de_resumo_de_sessao.html: este guia visual.MODELOS_DOWNLOAD.txt: links dos modelos + onde colocar cada arquivo.SMOKE_TEST_10_MIN.md: checklist rápido para validar instalação em ~10 minutos.requirements.manual.txt: referência de dependências para instalação manual.tests/: testes automatizados (opcional).
Estrutura runtime incluída vazia: data/uploads/, data/transcribe_cache/, downloads/, logs/.
2) Requisitos obrigatórios
- Python 3.11+ (3.13 também funciona) - python.org/downloads/windows
- FFmpeg (full shared) - gyan.dev/ffmpeg/builds
- Microsoft VC++ Redistributable (x64) - learn.microsoft.com VC++ redist
Recomendado para desempenho: Driver NVIDIA (link) e CUDA Toolkit (link).
- Internet necessária na primeira execução (download de pacotes/modelos).
- Espaço livre recomendado: 15 GB+.
3) Instalação do zero (sem Git)
- Baixe o ZIP do projeto.
- Descompacte em uma pasta local (ex.:
C:\midia-faren). - Execute
executar.bat. - Aguarde os passos de instalação/validação.
- Acesse
http://127.0.0.1:5000/.
3.1) Fluxo GitHub (clonar, commitar e publicar)
Repositório oficial: https://github.com/FarenRavirar/midia-faren/
Clonar o repositório
git clone https://github.com/FarenRavirar/midia-faren.git cd midia-faren
Para trabalhar só no pacote de instalação:
cd instalacao\\midia-faren
Commits e push (fluxo básico)
git status git add . git commit -m \"chore: atualizacao da documentacao e instalacao\" git push origin main
Baixar ZIP sem Git
No GitHub: Code -> Download ZIP.
Publicar ZIP em Releases (recomendado)
- Criar tag e enviar:
git tag -a v1.0.0 -m \"release v1.0.0\" git push origin v1.0.0
- No GitHub:
Releases->Draft a new release, selecione a tag e anexe o ZIP do pacote. - Gerar ZIP localmente (PowerShell):
Compress-Archive -Path \".\\instalacao\\midia-faren\\*\" -DestinationPath \".\\instalacao\\midia-faren-v1.0.0.zip\" -Force
4) O que o executar.bat faz
- Cria/reutiliza venv local
.venv_cuda. - Instala base:
flask,requests,yt-dlp. - Instala stack IA fixada:
torch==2.8.0+cu128torchaudio==2.8.0+cu128faster-whisper==1.2.1whisperx==3.8.0ctranslate2==4.7.1
- Remove
torchcodecpor instabilidade neste stack no Windows. - Valida imports e sobe o Flask.
Flags úteis
--check: só valida ambiente.--setup-env: força reinstalação.--recreate-venv: recria venv.--ffmpeg-path-on: força PATH FFmpeg da sessão.--ffmpeg-path-auto: injeta só se FFmpeg não estiver no PATH.--ffmpeg-path-off: não injeta PATH (padrão).
executar.bat --setup-env --recreate-venv --ffmpeg-path-auto
5) FFmpeg: como garantir detecção
Ordem de busca do app:
tools\ffmpeg\bin\ffmpeg.exeC:\tools\ffmpeg\ffmpeg-7.1.1-full_build-shared\bin\ffmpeg.exeffmpegno PATH
Teste:
ffmpeg -version
6) GPU vs CPU (comportamento real)
- Roda com e sem CUDA.
- Com CUDA: mais rápido.
- Sem CUDA: funciona em CPU (mais lento).
.venv_cuda\Scripts\python -c "import torch; print(torch.cuda.is_available(), torch.version.cuda)"
7) Backends de transcrição
Disponíveis na UI: whisper_cpp, faster_whisper, whisperx.
Recursos: chunking + overlap, checkpoint por chunk, retomada/reprocessamento, guardrails anti-loop, glossário persistente.
8) Modelos (qualidade x velocidade)
| Modelo | Velocidade | Qualidade | Link |
|---|---|---|---|
| tiny | Muito alta | Baixa | openai/whisper-tiny |
| base | Alta | Baixa/média | openai/whisper-base |
| small | Média/alta | Média | openai/whisper-small |
| medium | Média | Boa | openai/whisper-medium |
| large-v3 | Mais lento | Muito alta | openai/whisper-large-v3 |
| distil-large-v3 | Mais rápido | Próxima do large-v3 | distil-whisper/distil-large-v3 |
Arquivo de referência: MODELOS_DOWNLOAD.txt.
Onde cada modelo fica
faster_whisper/whisperx: download automático; cache em%USERPROFILE%\.cache\huggingface\hub.whisper_cpp: baixarggml-*.bine copiar paratranscriber\models\.
9) Importante sobre whisper_cpp neste pacote
Para manter o repositório leve no GitHub, binários grandes e modelos .bin do whisper_cpp não são incluídos.
faster_whisperewhisperxcontinuam prontos.- Se quiser
whisper_cpp, siga:
- Abrir
MODELOS_DOWNLOAD.txt. - Baixar modelos
ggml-*.bin. - Copiar para
transcriber\models\. - Selecionar backend/modelo na UI.
10) Fluxo recomendado: Craig -> Transcrição estruturada -> NotebookLM
Regra principal
Para resumo de sessão no NotebookLM, a fonte principal deve ser a transcrição em texto (TXT/SRT), com timestamps corretos e separação por falantes/personagens quando aplicável.
O M4A mixado pode ser usado como fonte complementar, mas não substitui a transcrição estruturada.
Pipeline recomendado no projeto
- Gerar transcrição completa na aba Transcrição.
- Confirmar saída em
.txte.srtcom marcação temporal e falantes. - Revisar trecho final para evitar cauda repetitiva/loop.
- (Opcional) gerar M4A em Conversor -> Mixagem.
- Acessar NotebookLM.
- Criar notebook e enviar primeiro TXT/SRT.
- Usar o prompt da seção 10.2 para gerar o resumo.
10.1 Passo a passo no NotebookLM
- Acesse NotebookLM.
- Crie novo notebook.
- Adicione a transcrição (
.txtou.srt) como fonte principal. - Aguarde indexação da fonte.
- (Opcional) adicione o M4A como fonte complementar.
- Cole o prompt da seção 10.2 no chat.
- Idioma: Português (Brasil).
10.2 Prompt pronto (modelo genérico)
Gere um resumo da sessão de RPG baseada na transcrição "[nome da transcrição]" no cenário "[nome do cenário]".
Quero um texto em formato de conto narrado em primeira pessoa do plural ("nós"), como se um dos jogadores estivesse contando para amigos o que aconteceu.
Regras do resultado:
1) Não faça análise técnica da mesa.
2) Não foque em elogiar ou exaltar pessoas específicas.
3) Conte os acontecimentos da sessão com narrativa fluida e empolgante.
Estrutura esperada:
1) Abertura da sessão:
- como nós chegamos;
- contexto inicial do local;
- quem eram os personagens presentes.
2) Desenvolvimento:
- conflitos e tensões;
- estratégias que nós tentamos;
- decisões e indecisões;
- reviravoltas, surpresas e consequências;
- acontecimentos importantes em ordem clara.
3) Fechamento:
- estado final do grupo;
- perguntas em aberto;
- gancho para continuação.
Diretriz de fidelidade:
- Use os nomes e fatos das fontes enviadas (transcrição com timestamps/falantes + notas de contexto), sem inventar fatos fora do material.
- Se algo estiver ambíguo, indique como possibilidade em vez de afirmar com certeza.
Final obrigatório (adapte ao contexto):
"Vamos ver aonde essa trama vai nos levar na próxima sessão."
10.3 Bloco de notas de contexto
[NOTAS DE CONTEXTO DA SESSAO] Nome do audio: [nome do audio] Nome do cenario: [nome do cenario] Sistema: [sistema de RPG] Resumo do contexto inicial: [contexto inicial da sessao] Personagens de jogadores: - Jogador: [nome do jogador 1] Personagem: [nome do personagem 1] Conceito: [raca/classe/profissao] Vinculo ou origem: [faccao/cidade/clan/grupo] Motivacao atual: [objetivo na sessao] - Jogador: [nome do jogador 2] Personagem: [nome do personagem 2] Conceito: [raca/classe/profissao] Vinculo ou origem: [faccao/cidade/clan/grupo] Motivacao atual: [objetivo na sessao] NPCs importantes: - NPC: [nome do NPC 1] Papel na historia: [funcao] Relacao com o grupo: [como influencia o grupo] - NPC: [nome do NPC 2] Papel na historia: [funcao] Relacao com o grupo: [como influencia o grupo] Termos e nomes que nao devem ser corrigidos: - [termo 1] - [termo 2] - [local 1] Observacoes de pronuncia ou escrita: - [nome dificil 1] -> [forma correta] - [nome dificil 2] -> [forma correta]
11) Verificações pós-instalação
.venv_cuda\Scripts\python -c "import flask,requests,yt_dlp; print('core_ok')"
.venv_cuda\Scripts\python -c "import torch; print(torch.__version__, torch.cuda.is_available(), torch.version.cuda)"
.venv_cuda\Scripts\python -c "import importlib.metadata as md; print(md.version('whisperx'), md.version('faster-whisper'), md.version('ctranslate2'))"
12) Troubleshooting rápido
ffmpeg não encontrado
- Reinstale FFmpeg full shared.
- Valide
ffmpeg -version. - Use
executar.bat --ffmpeg-path-auto.
Erro de dependência Python
executar.bat --setup-env --recreate-venv
Transcrição lenta
- Use modelo menor (
small/medium). - Use backend
faster_whisper. - Verifique se CUDA está ativo.
Loop/repetição no final
- Ajuste chunk/overlap.
- Revise glossário/contexto.
- Use reprocessamento de chunk.
13) Publicação no GitHub
.gitignorejá preparado para dados locais/caches.- Sem caminhos pessoais hardcoded.
- Sem venv embutido.
- Sem binários gigantes de
whisper_cpp.
14) Smoke test de 10 minutos
Checklist completo no arquivo: SMOKE_TEST_10_MIN.md.
Critério de aprovação rápido:
- App sobe e a UI abre.
- Conversão curta termina com sucesso.
- Transcrição curta gera
.txte.srt. - Cancelamento de job funciona.
- Sem erro crítico persistente no final de
logs/app.log.
15) Checklist final
- Flask inicia sem erro e abre no navegador.
- FFmpeg detectado e conversão funciona.
- Transcrição gera TXT/SRT coerentes.
- Glossário salva e aplica corretamente.
- Cancelamento de job interrompe de fato.
- Sem loop patológico na cauda.
- TXT/SRT final com timestamps e falantes pronto para NotebookLM.
- M4A de mixagem opcional disponível como fonte complementar.
Créditos: desenvolvido por Paulo "Faren" Lima, do Artifício RPG.